Introduction
The ECMWF operational ensemble forecasts for the western Mediterranean region exhibited high uncertainty while Hurricane Nadine was slowly moving over the eastern N.Atlantic in Sept. 2012. Interaction with an Atlantic cut-off low produced a bifurcation in the ensemble and significant spread, which controls both the track of Hurricane Nadine and the synoptic conditions downstream.
The HyMEX (Hydrological cycle in Mediterranean eXperiment) field campaign was also underway and forecast uncertainty was a major issue for planning observations during the first special observations period of the campaign.
This interesting case study examines the forecasts in the context of the interaction between Nadine and the Atlantic cut-off low in the context of ensemble forecasting. It will explore the scientific rationale for using ensemble forecasts, why they are necessary and they can be interpreted, particularly in a "real world" situation of forecasting for a observational field campaign.
Pantillon, F., Chaboureau, J.-P. and Richard, E. (2015), 'Vortex-vortex interaction between Hurricane Nadine and an Atlantic cutoff dropping the predictability over the Mediterranean, http://onlinelibrary.wiley.com/doi/10.1002/qj.2635/abstract
In this case study
In the exercises for this interesting case study we will:
- Study the development of Hurricane Nadine and the interaction with the Atlantic cut-off low using the ECMWF analyses.
- Study the performance of the ECMWF high resolution (HRES) deterministic forecast of the time.
- Use the operational ensemble forecast to look at the forecast spread and understand the uncertainty downstream of the interaction.
- Compare a reforecast using the May/2016 ECMWF operational ensemble with the 2012 ensemble forecasts.
- Use principal component analysis (PCA) with clustering techniques (see Pantillon et al) to characterize the behaviour of the ensembles.
Table of contents
If the plotting produces thick contour lines and large labels, ensure that the environment variable LC_NUMERIC="C" is set before starting metview.
Caveat on use of ensembles for case studies
In practise many cases are aggregated in order to evaluate the forecast behaviour of the ensemble. However, it is always useful to complement such assessments with case studies of individual events, like the one in this exercise, to get a more complete picture of IFS performance and identify weaker aspects that need further exploration.
Obtaining the exercises
The exercises described below are available as a set of Metview macros with the accompanying data. This is available as a downloadable tarfile for use with Metview. It is also available as part of the OpenIFS/Metview virtual machine, which can be run on different operating systems.
For more details of the OpenIFS virtual machine and how to get the workshop files, please contact: openifs-support@ecmwf.int.
ECMWF operational forecasts
At the time of this case study in 2012, ECMWF operational forecasts consisted of:
- HRES : spectral T1279 (16km grid) highest resolution 10 day deterministic forecast.
- ENS : spectral T639 (34km grid) resolution ensemble forecast (50 members) is run for days 1-10 of the forecast, T319 (70km) is run for days 11-15.
At the time of this workshop in 2016, the ECMWF operational forecasts has been upgraded compared to 2012 and consisted of:
- HRES/2016 : spectral T1279 with an octahedral grid configuration providing highest resolution of 9km.
- ENS/2016 : spectral T639 with an octahedral grid configuration providing highest resolution of 18km for all 15 days of the forecast.
Please follow this link to see more details on changes to the ECMWF IFS forecast system (http://www.ecmwf.int/en/forecasts/documentation-and-support/changes-ecmwf-model)
Virtual machine
If using the OpenIFS/Metview virtual machine with these exercises the recommended memory is at least 6Gb, the minimum is 4Gb. If using 4Gb, do not use more than 2 parameters per plot.
These exercises use a relatively large domain with high resolution data. Some of the plotting options can therefore require significant amounts of memory. If the virtual machine freezes when running metview, please restart the VM and increase the memory assigned to the VM
Starting up metview
To begin:
metview &
Please enter the folder 'openifs_2016' to begin working.
Saving images and printing
To save images during these exercises for discussion later, you can either use:
"Export" button in Metview's display window under the 'File' menu to save to PNG image format. This will also allow animations to be saved into postscript.
or use the following command to take a 'snapshot' of the screen:
ksnapshot
Exercise 1. The ECMWF analysis
Hurricane Nadine and the cut-off low
For these tasks, use the metview icons in the row labelled 'Analysis'

an_1x1.mv : this plots horizontal maps of parameters from the ECMWF analyses overlaid on one plot.
an_2x2.mv : this plots horizontal maps of parameters from the ECMWF analyses four plots to a page (two by two).
an_xs.mv : this plots vertical cross-sections of parameters from the ECMWF analyses.
Task 1: Mean-sea-level pressure and track
Right-click on the 'an_1x1.mv' icon and select the 'Visualise' menu item (see figure right)
After a pause, this will generate a map showing mean-sea-level pressure (MSLP).

Plot track of Nadine. Drag the mv_track.mv icon onto the map.
This will add the track of Hurricane Nadine. Although the full track of the tropical storm is shown from the 10-09-2012 to 04-10-2016, the ECMWF analyses (for the purpose of this study) only show 15-09-2012 to 25-09-2012.
In the plot window, use the play button in the animation controls  to animate the map and follow the development and track of Hurricane Nadine.
to animate the map and follow the development and track of Hurricane Nadine.
You can use the 'Speed' menu to change the animation speed (each frame is every 6 hours).
If the contour lines appear jagged, in the plot window, select the menu item 'Tools -> Antialias'.
Close unused plot windows!
Please close any unused plot windows if using a virtual machine. This case study uses high resolution data over a relatively large domain. Multiple plot windows can therefore require significant amounts of computer memory which can be a problem for virtual machines with restricted memory.
Task 2: MSLP and 500hPa geopotential height
This task creates Figure 2. from Pantillon et al.
Right-click the mouse button on the 'an_1x1.mv' icon and select the 'Edit' menu item.
An edit window appears that shows the Metview macro code used to generate the plot. During these exercises you can change the top lines of these macros to alter the choice of parameters and plot types.
#Available parameters: # mslp,t2,wind10,speed10,sst # t,z,pt,eqpt [850,700,500,200] # wind,speed,r[925,850,700,500,200] # w700, vo850, pv320K
The surface fields (single level) are: MSLP (mean-sea-level-pressure), 2-metre temperature (t2), 10-metre wind arrows (wind10), wind-speed at 10m (sqrt(u^2+v^2): speed10), sea-surface temperature (sst).
The upper level fields are: temperature (t), geopotential (z), potential temperature (pt), equivalent potential temperature (eqpt), wind arrows (wind), wind-speed (speed), relative humidity (r).
These fields have a list of available pressure levels in square brackets.
To plot upper level fields, specify the pressure level after the name. e.g. z500 would plot geopotential at 500hPa.
Some extra fields are also provided: vertical velocity at 700hPa (w700), relative vorticity at 850hPa (vo850) and potential vorticity at 320K.
Wind fields are normally plotted as coloured arrows. To plot them as wind barbs add the suffix '.flag'. e.g. "wind10.flag" will plot 10m wind as barbs.
With the edit window open, find the line that defines 'plot1':
#Define plot list (min 1- max 4) plot1=["mslp"] # use square brackets when overlaying multiple fields per plot
Change this line to:
plot1=["z500.s","mslp"]
The suffix '.s' means plot the 500hPa geopotential as a shaded plot instead of using contours (this style is not available for all fields).
Click the play button and then animate the map that appears.
Change the value of "plot1" again to animate the PV at 320K, plot1=["pv320K"] (similar to Figure 13 in Pantillon et al).
You might add the mslp or z500 fields to this plot. e.g. plot1=["pv320K","z500"], (don't put z500.s as this will use shading not contours).
Or produce two plots, one with PV at 320K, the other with z500 or MSLP and put them side by side on the screen.
From the animation of the z500 and mslp fields: (as in Figure 1. from Pantillon et al.)
Q. When does the cut-off low form (see z500)?
Q. From the PV at 320K (and z500), what is different about the upper level structures of Nadine and the cut-off low? (also look at the cross-section plot)
Task 3: Changing geographical area
Right-click on 'an_1x1.mv' icon and select 'Edit'.
In the edit window that appears
#Map type: 0=Atl-an, 1: Atl-fc, 2: France mapType=0
With mapType=0, the map covers a large area centred on the Atlantic suitable for plotting the analyses and track of the storm (this area is only available for the analyses).
With mapType=1, the map also covers the Atlantic but a smaller area than for the analyses. This is because the forecast data in the following exercises does not cover as large a geographical area as the analyses.
With mapType=2, the map covers a much smaller region centred over France.
Change, mapType=0 to mapType=1 then click the play button ![]() at the top of the window.
at the top of the window.
Repeat using mapType=2 to see the smaller region over France.
These different regions will be used in the following exercises.
Animate the storm on this smaller geographical map.
Task 4: Wind fields, sea-surface temperature (SST)
The 'an_2x2.mv' icon allows for plotting up to 4 separate figures on a single frame. This task uses this icon to plot multiple fields.
Right-click on the 'an_2x2.mv' icon and select the 'Edit' menu item.
#Define plot list (min 1- max 4) plot1=["mslp"] plot2=["wind10"] plot3=["speed500","z500"] plot4=["sst"]
Click the play button ![]() at the top of the window to run this macro with the existing plots as shown above.
at the top of the window to run this macro with the existing plots as shown above.
Each plot can be a single field or overlays of different fields.
Wind parameters can be shown either as arrows or as wind flags ('barbs') by adding '.flag' to the end of variable name e.g. "wind10.flag".
Animating. If only one field on the 2x2 plot animates, make sure the menu item 'Animation -> Animate all scenes' is selected.
Plotting may be slow depending on the computer used. This reads a lot of data files.
Q. What do you notice about the SST field?
Task 5: Satellite images
Open the folder 'satellite' by doubling clicking (scroll the window if it is not visible).
This folder contains satellite images (water vapour, infra-red, false colour) for 00Z on 20-09-2012 and animations of the infra-red and water vapour images.
Double click the images to display them.
Use the an_1x1.mv and/or the an_2x2.mv macros to compare the ECMWF analyses with the satellite images.
Task 6: Cross-sections
The last task in this exercise is to look at cross-sections through Hurricane Nadine and the cut-off low.
Right click on the icon 'an_xs.mv', select 'Edit' and push the play ![]() button.
button.
The plot shows potential vorticity (PV), wind vectors and potential temperature roughly through the centre of the Hurricane and the cut-off low. The red line on the map of MSLP shows the location of the cross-section.
Q. Look at the PV field, how do the vertical structures of Nadine and the cut-off low differ?
Changing forecast time
Cross-section data is only available every 24hrs.
This means the 'steps' value in the macros is only valid for the times: [2012-09-20 00:00], [2012-09-21 00:00], [2012-09-22 00:00], [2012-09-23 00:00], [2012-09-24 00:00], [2012-09-25 00:00]
To change the date/time of the plot, edit the macro and change the line:
steps=[2012-09-22 00:00]
Changing fields
A reduced number of fields is available for cross-sections: temperature (t), potential temperature (pt), relative humidity (r), potential vorticity (pv), vertical velocity (w), wind-speed (speed; sqrt(u*u+v*v)) and wind vectors (wind3).
Changing cross-section location
#Cross section line [ South, West, North, East ] line = [30,-29,45,-15]
The cross-section location (red line) can be changed in this macro by defining the end points of the line as shown above.
Remember that if the forecast time is changed, the storm centres will move and the cross-section line will need to be repositioned to follow specific features. This is not computed automatically, but must be changed by altering the coordinates above.
Exercise 2: The operational HRES forecast
Recap
The ECMWF operational deterministic forecast is called HRES. At the time of this case study, the model ran with a spectral resolution of T1279, equivalent to 16km grid spacing.
Only a single forecast is run at this resolution as the computational resources required are demanding. The ensemble forecasts are run at a lower resolution.
Before looking at the ensemble forecasts, first understand the performance of the operational HRES forecast of the time.
Available forecast
Data is provided for a single 5 day forecast starting from 20th Sept 2012, as used in the paper by Pantillon et al.
HRES data is provided at the same resolution as the operational model, in order to give the best representation of the Hurricane and cut-off low iterations. This may mean that some plotting will be slow.
Available parameters
A new parameter is total precipitation : tp.
The parameters available in the analyses are available in the forecast data.
Available plot types

For this exercise, you will use the metview icons in the row labelled 'HRES forecast' as shown above.
hres_rmse.mv : this plots the root-mean-square-error growth curves for the operational HRES forecast compared to the ECMWF analyses.
hres_1x1.mv & hres_2x2.mv : these work in a similar way to the same icons used in the previous task where parameters from a single lead time can be plotted either in a single frame or 4 frame per page.
hres_to_an_diff.mv : this plots a single parameter as a difference map between the operational HRES forecast and the ECMWF analysis. Use this to understand the forecast errors.
Forecast performance
Task 1: Forecast error
In this task, we'll look at the difference between the forecast and the analysis by using "root-mean-square error" (RMSE) curves as a way of summarising the performance of the forecast.
Root-mean square error curves are a standard measure to determine forecast error compared to the analysis and several of the exercises will use them. The RMSE is computed by taking the square-root of the mean of the forecast difference between the HRES and analyses. RMSE of the 500hPa geopotential is a standard measure for assessing forecast model performance at ECMWF (for more information see: http://www.ecmwf.int/en/forecasts/quality-our-forecasts).
Right-click the hres_rmse.mv icon, select 'Edit' and plot the RMSE curve for z500.
Repeat for the mean-sea-level pressure mslp.
Repeat for both geographical regions: mapType=1 (Atlantic) and mapType=2 (France).
Q. What do the RMSE curves show?
Q. Why are the curves different between the two regions?
Task 2: Compare forecast to analysis
Use the hres_to_an_diff.mv icon and plot the difference map between the HRES forecast and the analysis first for z500 and then mslp (change plot1 from z500 to mslp).
Q. What differences can be seen?
Q. How well did the forecast position the Hurricane and cut-off N.Atlantic low?
If time: look at other fields to study the behaviour of the forecast.
Task 3: Precipitation over France
This task produces a plot similar to Figure 2 in Pantillon et al.
Choose a hres macro to use, plot the total precipitation (parameter: tp), near surface wind field, relative humidity (and any other parameters of interest).
As for the analyses, the macros hres_1x1.mv, hres_2x2.mv and hres_xs.mv can be used to plot and animate fields or overlays of fields from the HRES forecast.
Q. Was it a good or bad forecast? Why?
Suggested plots for discussion
The following is a list of parameters and plots that might be useful to produce for later group discussion. Choose a few plots and use both the HRES forecast and the analyses.
For help on how to save images, see the beginning of this tutorial.
- Geopotential at 500hPa + MSLP : primary circulation, Figure 1 from Pantillon et al.
- MSLP + 10m winds : interesting for Nadine's tracking and primary circulation
- MSLP + relative humidity at 700hPa + vorticity at 850hPa : low level signature of Nadine and disturbance associated with the cutoff low, with mid-level humidity of the systems.
- Geopotential + temperature at 500hPa : large scale patterns, mid-troposphere position of warm Nadine and the cold Atlantic cutoff
- Geopotential + temperature at 850hPa : lower level conditions, detection of fronts
- 320K potential vorticity (PV) + MSLP, and,
- 500hPa relative vorticity (see Fig. 14 in Pantillon) : upper level conditions, upper level jet and the cutoff signature in PV, interaction between Nadine and the cut-off low.
- Winds at 850hPa + vertical velocity at 700hPa (+MSLP) : focus on moist and warm air in the lower levels and associated vertical motion. Should not be a strong horizontal temperature gradient around Nadine, the winds should be stronger for Nadine than for the cutoff.
- 10m winds + total precipitation (+MSLP) : compare with Pantillon Fig.2., impact on rainfall over France.
- Potential temperature + potential vorticity: to characterize the cold core and warm core structures of Hurricane Nadine and the cut-off low.
- Humidity + vertical motion : another view of the cold core and warm core structures of Hurricane Nadine and the cut-off low.
- PV + vertical velocity (+ relative humidity) : a classical cross-section to see if a PV anomaly is accompanied with vertical motion or not.
Exercise 3 : The operational ensemble forecasts
Recap
- ECMWF operational ensemble forecasts treat uncertainty in both the initial data and the model.
- Initial analysis uncertainty: sampled by use of Singular Vectors (SV) and Ensemble Data Assimilation (EDA) methods. Singular Vectors are a way of representing the fastest growing modes in the initial state.
- Model uncertainty: sampled by use of stochastic parametrizations.
- Ensemble mean : the average of all the ensemble members. Where the spread is high, small scale features can be smoothed out in the ensemble mean.
- Ensemble spread : the standard deviation of the ensemble members, represents how different the members are from the ensemble mean.
The ensemble forecasts
In this case study, there are two operational ensemble datasets and additional datasets created with the OpenIFS model, running at lower resolution, where the initial and model uncertainty are switched off in turn. The OpenIFS ensembles are discussed in more detail in later exercises.
An ensemble forecast consists of:
- Control forecast (unperturbed)
- Perturbed ensemble members. Each member will use slightly different initial data conditions and include model uncertainty pertubations.
2012 Operational ensemble
ens_oper: This dataset is the operational ensemble from 2012 and was used in the Pantillon et al. publication. A key feature of this ensemble is use of a climatological SST field (you would have seen this in the earlier tasks).
2016 Operational ensemble
ens_2016: This dataset is a reforecast of the 2012 event using the ECMWF operational ensemble of March 2016. Two key differences between the 2016 and 2012 operational ensembles are: higher horizontal resolution, and coupling of NEMO ocean model to provide SST from the start of the forecast.
The analysis was not rerun for 20-Sept-2012. This means the reforecast using the 2016 ensemble will be using the original 2012 analyses. Also only 10 ensemble data assimilation (EDA) members were used in 2012, whereas 25 are in use for 2016 operational ensembles, so each EDA member will be used multiple times for this reforecast. This will impact on the spread and clustering seen in the tasks in this exercise.
Ensemble exercise tasks
Visualising ensemble forecasts can be done in various ways. During this exercise we will use a number of visualisation techniques in order to understand the errors and uncertainties in the forecast,
Key parameters: MSLP, z500, and total precipitation (tp) over France. We suggest concentrating on viewing these fields. If time, visualize other parameters (e.g. PV320K).

Available plot types

For these exercises please use the Metview icons in the row labelled 'ENS'.
ens_rmse.mv : this is similar to the hres_rmse.mv in the previous exercise. It will plot the root-mean-square-error growth for the ensemble forecasts.
ens_to_an.mv : this will plot (a) the mean of the ensemble forecast, (b) the ensemble spread, (c) the HRES deterministic forecast and (d) the analysis for the same date.
ens_to_an_runs_spag.mv : this plots a 'spaghetti map' for a given parameter for the ensemble forecasts compared to the analysis. Another way of visualizing ensemble spread.
stamp.mv : this plots all of the ensemble forecasts for a particular field and lead time. Each forecast is shown in a stamp sized map. Very useful for a quick visual inspection of each ensemble forecast.
stamp_diff.mv : similar to stamp.mv except that for each forecast it plots a difference map from the analysis. Very useful for quick visual inspection of the forecast differences of each ensemble forecast.
Additional plots for further analysis:

pf_to_cf_diff.mv : this useful macro allows two individual ensemble forecasts to be compared to the control forecast. As well as plotting the forecasts from the members, it also shows a difference map for each.
ens_to_an_diff.mv : this will plot the difference between the ensemble control, ensemble mean or an individual ensemble member and the analysis for a given parameter.
Group working
If working in groups, each group could follow the tasks below with a different ensemble forecast. e.g. one group uses the 'ens_oper', another group uses 'ens_2016' and so on.
Choose your ensemble dataset by setting the value of 'expId', either 'ens_oper' or 'ens_2016' for this exercise.
One of the OpenIFS ensembles could also be used but it's recommended one of the operational ensembles is studied first.
#The experiment. Possible values are: # ens_oper = operational ENS # ens_2016 = 2016 operational ENS expId="ens_oper"
Ensemble forecast performance
In these tasks, the performance of the ensemble forecast is studied.
Q. How does the ensemble mean MSLP and Z500 fields compare to the HRES forecast and analysis?
Q. Examine the initial diversity in the ensemble and how the ensemble spread and error growth develops. What do the extreme forecasts look like?
Q. Are there any members that consistently provide a better forecast?
Q. Comparing the two ensembles, ens_oper and ens_2016, which is the better ensemble for this case study?
Task 1: RMSE "plumes"
This is similar to task 1 in exercise 2, except the RMSE curves for all the ensemble members from a particular forecast will be plotted.
Right-click the ens_rmse.mv icon, select 'Edit' and plot the curves first for 'mslp' and then for 'z500' (change the param field to mslp, run the macro and then change to z500 and run again).
Change 'expID' for your choice of ensemble.
clustersId="off"
Clustering will be used in later tasks.
Q. How do the HRES, ensemble control forecast and ensemble mean compare?
Q. How do the ensemble members behave, do they give better or worse forecasts?
Q. Compare with ens_2016 ensemble, or with a different group. How does the performance of the HRES and control forecast change?
There might be some evidence of clustering in the ensemble plumes.
There might be some individual forecasts that give a lower RMS error than the control forecast.
If time:
- Explore the plumes from other variables.
- Do you see the same amount of spread in RMSE from other pressure levels in the atmosphere?
Task 2: Ensemble spread
In the previous task, uncertainty in the forecast by starting from different initial conditions and the stochastic parameterizations can result in significant differences in the RMSE (for this particular case and geographical region).
This task will explore the difference in another way by looking at the 'ensemble spread'.
Use the ens_to_an.mv icon and first plot the MSLP and then z500 (set param to mslp, run the macro, then change param to z500 and run again).
This will produce plots showing: the mean of all the ensemble forecasts, the spread of the ensemble forecasts, the operational HRES deterministic forecast and the analysis.
Change 'expId' if required.
Animate this plot to see how the spread grows.
This macro can also be used to look at clusters of ensemble members. It will be used later in the clustering tasks. For this task, make sure all the members of the ensemble are used.
#ENS members (use ["all"] or a list of members like [1,2,3] members=["all"] #[1,2,3,4,5] or ["all"] or ["cl.example.1"]
Q. How does the mean of the ensemble forecasts compare to the HRES & analysis?
Q. Does the ensemble spread capture the error in the forecast?
Q. What other comments can you make about the ensemble spread?
Task 3: Spaghetti plots - another way to visualise spread
A "spaghetti" plot is where a single contour of a parameter is plotted for all ensemble members. It is another way of visualizing the differences between the ensemble members and focussing on features.
Use the ens_to_an_runs_spag.mv icon. Plot and animate either the MSLP or z500 fields using your suitable choice for the contour level. Find a value that highlights the low pressure centres. Note that not all members may reach the low pressure set by the contour.
If the contour value is not set correctly, no lines will appear. Use the 'cursor data' icon ![]() at the top of the plot to inspect the data values.
at the top of the plot to inspect the data values.
The red contour line shows the control forecast of the ensemble.
Note that this macro may animate slowly because of the computations required.
Experiment with changing the contour value and (if time) plotting other fields.
Task 4: Visualise ensemble members and differences
So far we have been looking at reducing the information in some way to visualise the ensemble.
Stamp maps are used to visualise all the ensemble members as normal maps. These are small, stamp sized contour maps plotted for each ensemble member using a small set of contours.
There are two icons to use, stamp.mv and stamp_diff.mv.
Use stamp.mv to first plot the MSLP and then z500 fields in the ensemble (set param='mslp', run the macro, then change to 'z500' and run again).
The stamp map is slow to plot as it reads a lot of data. Rather than animate each forecast step, a particular date can be set by changing the 'steps' variable.
#Define forecast steps steps=[2012-09-24 00:00,"to",2012-09-24 00:00,"by",6]
Make sure clustersId="off" for this task.
Precipitation over France
Use stamp.mv and plot total precipitation ('tp') over France (mapType=2) for 00Z 24-09-2012 (compare with Figure 2 in Pantillon).
Note, stamp_diff.mv cannot be used for 'tp' as there is no precipitation data in the analyses.
Difference stamp maps
Use the stamp_diff.mv plot to look at the differences between the ensemble members and the analysis. It can be easier to understand the difference in the ensembles by using difference stamp maps.
Q. Using the stamp and stamp difference maps, study the ensemble. Identify which ensembles produce "better" forecasts.
Q. Can you see any distinctive patterns in the difference maps?
Compare ensemble members to analysis
After visualizing the stamp maps, it can be useful to animate a comparison of individual ensemble members to the analyses.
ens_to_an_diff.mv and pf_to_cf_diff.mv can be used to compare ensemble members.
To animate the difference in MSLP of an individual ensemble member 30 to the analysis, edit the lines:
param="mslp" ensType="pf30"
To compare the control forecast:
ensType="cf"
Further analysis using ensembles
This will show the forecasts from the ensemble members and also their difference with the ensemble control forecast.
To animate the difference in MSLP with ensemble members '30' and '50', set:
param="mslp" pf=[30,50]
Compare the SST parameter used for the ens_oper and ens_2016 ensemble forecasts. The 2016 reforecast of this case study used a coupled ocean model unlike the 2012 ensemble and HRES forecast that used climatology for the first 5 days.
To show a cross-section of a particular ensemble member, use the macro 'ens_xs.mv'.
This works in the same way as the an_xs.mv and hres_xs.mv macros.
Find ensemble members that appear to produce a better forecast and look to see how the initial development in these members differs.
- Select 'better' forecasts using the stamp plots and use ens_to_an.mv to modify the list of ensemble plots.
- Use pf_to_cf_diff and ens_to_an_diff to take the difference between these perturbed ensemble member forecasts from the control and analyses to also look at this.
Q. Can you tell which area is more sensitive for the forecast?
Task 5: Cumulative distribution function
Recap
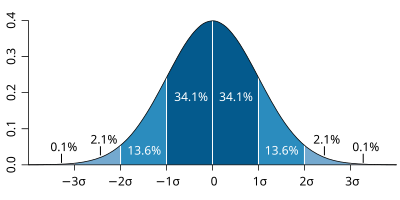
| The probability distribution function of the normal distribution or Gaussian distribution. The probabilities expressed as a percentage for various widths of standard deviations (σ) represent the area under the curve. |
|---|
Figure from Wikipedia. |
Cumulative distribution function for a normal |
|---|
Figure from Wikipedia. |
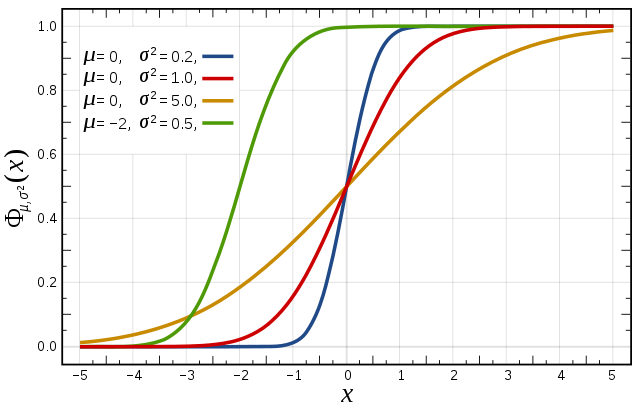
Cumulative distribution function (CDF)
The figures above illustrate the relationship between a normal distribution and its associated cumulative distribution function. The CDF is constructed from the area under the probability density function.
The CDF gives the probability that a value on the curve will be found to have a value less than or equal to the corresponding value on the x-axis. For example, in the figure, the probability for values less than or equal to X=0 is 50%.
The shape of the CDF curve is related to the shape of the normal distribution. The width of the CDF curve is directly related to the value of the standard deviation of the probability distribution function.
For an ensemble, the width is therefore related to the 'ensemble spread'.
For a forecast ensemble where all values were the same, the CDF would be a vertical straight line.
Plot the CDFs

This exercise uses the cdf.mv icon. Right-click, select 'Edit' and then:
- Plot the CDF of MSLP for Toulouse for your choice of ensemble
- Find a latitude/longitude point in the area of intense precipitation on 12Z 24/9/2012 (see Figure 2(c) Pantillon et al) and plot the CDF for MSLP (set station=[lat,lon] in the macro cdf.mv)
Note that only MSLP, 2m temperature (t2) and 10m wind-speed (speed10) are available for the CDF.
Make sure useClusters='off'.
Q. Compare the CDF from the different forecast ensembles; what can you say about the spread?
Exercise 4: Cluster analysis
The paper by Pantillon et al describes the use of clustering to identify the main scenarios among the ensemble members.
This exercise repeats some of the plots from the previous one but this time with clustering enabled.
Using clustering will highlight the ensemble members in each cluster in the plots.
In this exercise you will:
- Construct your own qualitative clusters by choosing members for two clusters
- Generate clusters using principal component analysis (similar to Pantillon et al).
Task 1: Create your own clusters
Clusters can be created manually from lists of the ensemble members.
Choose members for two clusters. The stamp maps are useful for this task.
From the stamp map of z500 at 24/9/2012 (t+96), identify ensemble members that represent the two most likely forecast scenarios.
It is usual to create clusters from z500 as it represents the large-scale flow and is not a noisy field. However, for this particular case study, the stamp map of 'tp' (total precipitation) over France is also very indicative of the distinct forecast scenarios. You might also try using other fields, such as 'mslp' or 'pv320K' to compare.
Right-click 'ens_oper_cluster.example.txt' and select Edit (or make a duplicate)
The file contains two example lines:
1# 2 3 4 9 22 33 40 2# 10 11 12 31 49
The first line defines the list of members for 'Cluster 1': in this example, members 2, 3, 4, 9, 22, 33, 40.
The second line defines the list of members for 'Cluster 2': in this example, members 10, 11, 12, 31, 49.
Change these two lines!.
Put your choice of ensemble member numbers for cluster 1 and 2 (lines 1 and 2 respectively).
You can create multiple cluster definitions by using the 'Duplicate' menu option to make copies of the file for use in the plotting macros..
The filename is important!
The first part of the name 'ens_oper' refers to the ensemble dataset and must match the expID name used in the plotting macro.
The 'example' part of the filename can be changed to your choice and should match the 'clustersId' value in the plotting macro.
As an example, a filename of: ens_2016_cluster.fred.txt would require 'expId=ens_2016', 'clustersId=fred' in the macro.
Use the clusters of ensemble members you have created in ens_oper_cluster.example.txt.
Change clustersId='example' in each of the ensemble plotting macros to enable cluster highlighting.
If you are looking at the 2016 reforecast, then make sure your file is called ens_2016_cluster.example.txt.
Replot ensembles:
RMSE: plot the RMSE curves using ens_rmse.mv. This will colour the curves differently according to which cluster they are in.
Stamp maps: the stamp maps will be reordered so the ensemble members will be grouped according to their cluster. Applies to stamp.mv and stamp_diff.mv. This will make it easier to see the forecast scenarios according to your clustering.
Spaghetti maps: with clusters enabled, two additional maps are produced which show the contour lines for each cluster.
The macro cluster_to_an.mv can be used to plot maps of parameters as clusters and compared to the analysis and HRES forecasts.
Use cluster_to_an.mv to plot z500 maps of your two clusters (equivalent to Figure 7 in Pantillon et al.)
If your cluster definition file is called 'ens_oper_cluster.example.txt', then Edit cluster_to_an.mv and set:
#ENS members (use ["all"] or a list of members like [1,2,3] members_1=["cl.example.1"] members_2=["cl.example.2"]
If your cluster definition file is has another name, e.g. ens_oper_cluster.fred.txt, then members_1=["cl.fred.1"].
Plot other parameters:
Plot total precipitation 'tp' for France (mapType=2). (Figure 8. in Pantillon et al.)
Q. Experiment with the choice of members in each clusters and plot z500 at t+96 (Figure 7 in Pantillon et al.). How similar are your cluster maps?
Q. What date/time does the impact of the different clusters become apparent?
Q. Are two clusters enough? Where do the extreme forecasts belong?
Task 2: Empirical orthogonal functions / Principal component analysis
A quantitative way of clustering an ensemble is by a principal component analysis using empirical orthogonal functions. These are computed from the differences between the ensemble members and the ensemble mean, then computing the eigenvalues and eigenfunctions of these differences (or variances) over all the members such that the difference of each member can be expressed as a linear combination of these eigenfuctions, also known as empirical orthogonal functions (EOFs).
Although geopotential height at 500hPa at 00 24/9/2012 is used in the paper by Pantillon et al. as it gives the best results, the steps described below can be used for any parameter at any step.

The eof.mv macro computes the EOFs and the clustering.
Always first use the eof.mv first for a given parameter, step and ensemble forecast (e.g. ens_oper or ens_2016) to create the cluster file.
Otherwise cluster_to_an.mv and other plots with clustering enabled will fail or plot with the wrong clustering of ensemble members.
If you change step or ensemble, recompute the EOFS and cluster definitions using eof.mv. Note however, that once a cluster has been computed, it can be used for all steps with any parameter.
If you rerun the eof.mv macro, it will write to a new file called for example 'ens_oper.eof.txt.latest' if the original file still exists. Make sure you rename this file to 'ens_oper.eof.txt' otherwise the plotting macros will continue to use the original ens_oper.eof.txt.
Edit 'eof.mv'
Set the parameter to use, choice of ensemble and forecast step required for the EOF computation:
param="z500" expId="ens_oper" steps=[2012-09-24 00:00]
Run the macro.
The above example will compute the EOFs of geopotential height anomaly at 500hPa using the 2012 operational ensemble at forecast step 00Z on 24/09/2012.
A plot will appear showing the first two EOFs (similar to Figure 5 in Pantillon et al.)
The geographical area for the EOF computation is: 35-55N, 10W-20E (same as in Pantillon et al). If desired it can be changed in eof.mv.
The eof.mv macro will create a text file with the cluster definitions, in the same format as described above in the previous task.
The filename will be different, it will have 'eof' in the filename to indicate it was created by using empirical orthogonal functions.
ens_oper_cluster.eof.txt
If a different ensemble forecast is used, for example ens_2016, the filename will be: ens_2016_cluster.eof.mv
This cluster definition file can then be used to plot any variable at all steps (as for task 1).
Q. What do the EOFs plotted by eof.mv show?
Q. Change the parameter used for the EOF (try the total precipitation 'tp' field). How does the cluster change?
Use the cluster definition file computed by eof.mv to the plot ensembles and maps with clusters enabled (as described for task 1, but this time with the 'eof' cluster file).
The macro cluster_to_an.mv can be used to plot maps of parameters as clusters and compared to the analysis and HRES forecasts.
Use cluster_to_an.mv to plot z500 and MSLP maps of the two clusters created by the EOF/PCA analysis (equivalent to Figure 7 in Pantillon et al.)
Edit cluster_to_an.mv and set:
#ENS members (use ["all"] or a list of members like [1,2,3] members_1=["cl.eof.1"] members_2=["cl.eof.2"]
Run the macro.
If time also look at the total precipitation (tp) over France and PV/320K.
Q. How similar is the PCA computed clusters to your manual clustering?
Q. Which cluster best represents the analysis?
Q. How useful is the cluster analysis as an aid to forecasting for HyMEX?
Q. Change the date/time used to compute the clusters. How does the variance explained by the first two clusters change? Is geopotential the best parameter to use?
Q. Compare ens_oper and ens_2016 (or with a different group). How do the clusters differ and why?
To change the number of clusters created by the EOF analysis, find the file in the folder 'base' called base_eof.mv.
Edit this file and near the top, change:
clusterNum=2
to
clusterNum=3
then select 'File' and 'Save' to save the changes.
Now if you run the eof.mv macro, it will generate a text file, such as ens_oper.eof.txt with 3 lines, one for each cluster. It will also show the 3 clusters as different colours.
You can use the 3 clusters in the cluster_to_an.mv macro, for example:
param="z500.s" expId="ens_oper" members_1=["cl.eof.1"] members_2=["cl.eof.3"]
would plot the mean of the members in the first and the third clusters (it's not possible to plot all three clusters together).
For those interested:
The code that computes the clusters can be found in the Python script: aux/cluster.py.
This uses the 'ward' cluster method from SciPy. Other cluster algorithms are available. See http://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.linkage.html#scipy.cluster.hierarchy.linkage
The python code can be changed to a different algorithm or the more adventurous can write their own cluster algorithm!
Exercise 5. Percentiles and probabilities
To further compare the 2012 and 2016 ensemble forecasts, plots showing the percentile amount and probabilities above a threshold can be made for total precipitation.
Use these icons:

Both these macros will use the 6-hourly total precipitation for forecast steps at 90, 96 and 102 hours, plotted over France.
Task 1. Plot percentiles of total precipitation
Edit the percentile_tp_compare.mv icon.
Set the percentile for the total precipitation to 75%:
#The percentile of ENS precipitation forecast perc=75
Run the macro and compare the percentiles from both the forecasts. Change the percentiles to see how the forecasts differ.
Task 2: Plot probabilities of total precipitation
This macro will produce maps showing the probability of 6-hourly precipitation for the same area as in Task 1.
In this case, the maps show the probability that total precipitation exceeds a threshold expressed in mm.
Edit the prob_tp_compare.mv and set the probability to 20mm:
#The probability of precipitation greater than prob=20
Run the macro and view the map. Try changing the threshold value and run.
Q. Using these two macros, compare the 2012 and 2016 forecast ensemble. Which was the better forecast for HyMEX flight planning?
Exercise 6. Exploring the role of uncertainty
To further understand the impact of the different types of uncertainty (initial and model), some forecasts with OpenIFS have been made in which the uncertainty has been selectively disabled. These experiments use a 40 member ensemble and are at T319 resolution, lower than the operational ensemble.
As part of this exercise you may have run OpenIFS yourself in the class to generate another ensemble; one participant per ensemble member.
Recap
- EDA is the Ensemble Data Assimilation.
- SV is the use of Singular Vectors to perturb the initial conditions.
- SPPT is the stochastic physics parametrisation scheme.
- SKEB is the stochastic backscatter scheme applied to the model dynamics.
Experiments available:
- Experiment id: ens_both. EDA+SV+SPPT+SKEB : Includes initial data uncertainty (EDA, SV) and model uncertainty (SPPT, SKEB)
- Experiment id: ens_initial. EDA+SV only : Includes only initial data uncertainty
- Experiment id: ens_model. SPPT+SKEB only : Includes model uncertainty only
The aim of this exercise is to use the same visualisation and investigation as in the previous exercises to understand the impact the different types of uncertainty make on the forecast.
A key difference between this exercise and the previous one is that these forecasts have been run at a lower horizontal resolution. In the exercises below, it will be instructive to compare with the operational ensemble plots from the previous exercise.
For this exercise, we suggest either each team focus on one of the above experiments and compare it with the operational ensemble. Or, each team member focus on one of the experiments and the team discuss and compare the experiments.
The different macros available for this exercise are very similar to those in previous exercises.

For this exercise, use the icons in the row labelled 'Experiments'. These work in a similar way to the previous exercises.
ens_exps_rmse.mv : this will produce RMSE plumes for all the above experiments and the operational ensemble.
ens_exps_to_an.mv : this produces 4 plots showing the ensemble spread from the OpenIFS experiments compared to the analysis.
ens_exps_to_an_spag.mv : this will produce spaghetti maps for a particular parameter contour value compared to the analysis.
ens_part_to_all.mv : this allows the spread & mean of a subset of the ensemble members to be compared to the whole ensemble.
For these tasks the Metview icons in the row labelled 'ENS' can also be used to plot the different experiments (e.g. stamp plots). Please see the comments in those macros for more details of how to select the different OpenIFS experiments.
Remember that you can make copies of the icons to keep your changes.
Task 1. RMSE plumes
Use the ens_exps_rmse.mv icon and plot the RMSE curves for the different OpenIFS experiments.
Compare the spread from the different experiments.
The OpenIFS experiments were at a lower horizontal resolution. How does the RMSE spread compare between the 'ens_oper' and 'ens_both' experiments?
Task 2. Ensemble spread and spaghetti plots
Use the ens_exps_to_an.mv icon and plot the ensemble spread for the different OpenIFS experiments.
Also use the ens_exps_to_an_spag.mv icon to view the spaghetti plots for MSLP for the different OpenIFS experiments.
Q. What is the impact of reducing the resolution of the forecasts? (hint: compare the spaghetti plots of MSLP with those from the previous exercise).
Q. How does changing the representation of uncertainty affect the spread?
Q. Which of the experiments ens_initial and ens_model gives the better spread?
Q. Is it possible to determine whether initial uncertainty or model uncertainty is more or less important in the forecast error?
If time:
- use the ens_part_to_all.mv icon to compare a subset of the ensemble members to that of the whole ensemble. Use the stamp_map.mv icon to determine a set of ensemble members you wish to consider (note that the stamp_map icons can be used with these OpenIFS experiments. See the comments in the files).
Task 3. What initial perturbations are important
The objective of this task is to identify what areas of initial perturbation appeared to be important for an improved forecast in the ensemble.
Using the macros provided:
- Find an ensemble member(s) that gave a consistently improved forecast and take the difference from the control.
- Step back to the beginning of the forecast and look to see where the difference originates from.
Use the large geographical area for this task. Use the MSLP and z500 fields (and any others you think are useful).
Task 4. Non-linear development
Ensemble perturbations are applied in positive and negative pairs. This is done to centre the perturbations about the control forecast.
So, for each computed perturbation, two perturbed initial fields are created e.g. ensemble members 1 & 2 are a pair, where number 1 is a positive difference compared to the control and 2 is a negative difference.
- Choose an odd & even ensemble pair (use the stamp plots). Use the appropriate icon to compute the difference of the members from the ensemble control forecast.
- Study the development of these differences using the MSLP and wind fields. If the error growth is linear the differences will be the same but of opposite sign. Non-linearity will result in different patterns in the difference maps.
- Repeat looking at one of the other forecasts. How does it vary between the different forecasts?
If time:
- Plot PV at 320K. What are the differences between the forecast? Upper tropospheric differences played a role in the interaction of Hurricane Nadine and the cut-off low.
Appendix
Further reading
For more information on the stochastic physics scheme in (Open)IFS, see the article:
Shutts et al, 2011, ECMWF Newsletter 129.
Acknowledgements
We gratefully acknowledge the following for their contributions in preparing these exercises. From ECMWF: Glenn Carver, Sandor Kertesz, Linus Magnusson, Iain Russell, Simon Lang, Filip Vana. From ENM/Meteo-France: Frédéric Ferry, Etienne Chabot, David Pollack and Thierry Barthet for IT support at ENM. We also thank the students who have participated in the training and workshop using this material for helping to improve it!